
We did a lot of exploratory work before coming up with the Turbo improvement we presented in Rails World. One of those experiments included diffing in the server instead of in the client.
The idea
The inspiration for this idea came, again, from Phoenix Live View, a library I find fascinating. Live View’s approach based on stateful WebSocket connections isn’t a good match for the Turbo’s progressive enhancement philosophy we love, but its rendering pipeline is an engineering wonder full of great ideas. I learned about morphing because Live View uses it at the end of the pipeline, and I thought of server-side diffing because that’s what Live View does at the beginning of it.
That’s why, after seeing that morphing worked in the scenarios we wanted, I decided to explore server-side diffing, too. Some fuzzy questions I had in mind were:
- Is sending a much smaller payload over the wire worth it — in practical terms — for our use cases?
- With
solid_cachein place, was it feasible to keep track of the served screens on a per-session basis to calculate and serve diffs over the wire? - Could we use a diffing approach that wasn’t as dependent on DOM ids as
morphdom? We hadn’t learned aboutidiomorphyet, andmorphdom’s dependency on DOM ids everywhere ruined the seamless sensations we were looking for.
The prototype
The prototype consisted of a Rails middleware that intercepted requests accepting a special mime type text/vnd.turbo-diff.json. The middleware relies on a diff engine to calculate the diff to serve. When the page contents are cached for a given session, the middleware seamlessly intercepts the response, calculates the diff, and serves it.
On the client side, it extends Turbo via standard events to include the new mime type and to apply the diff payloads.
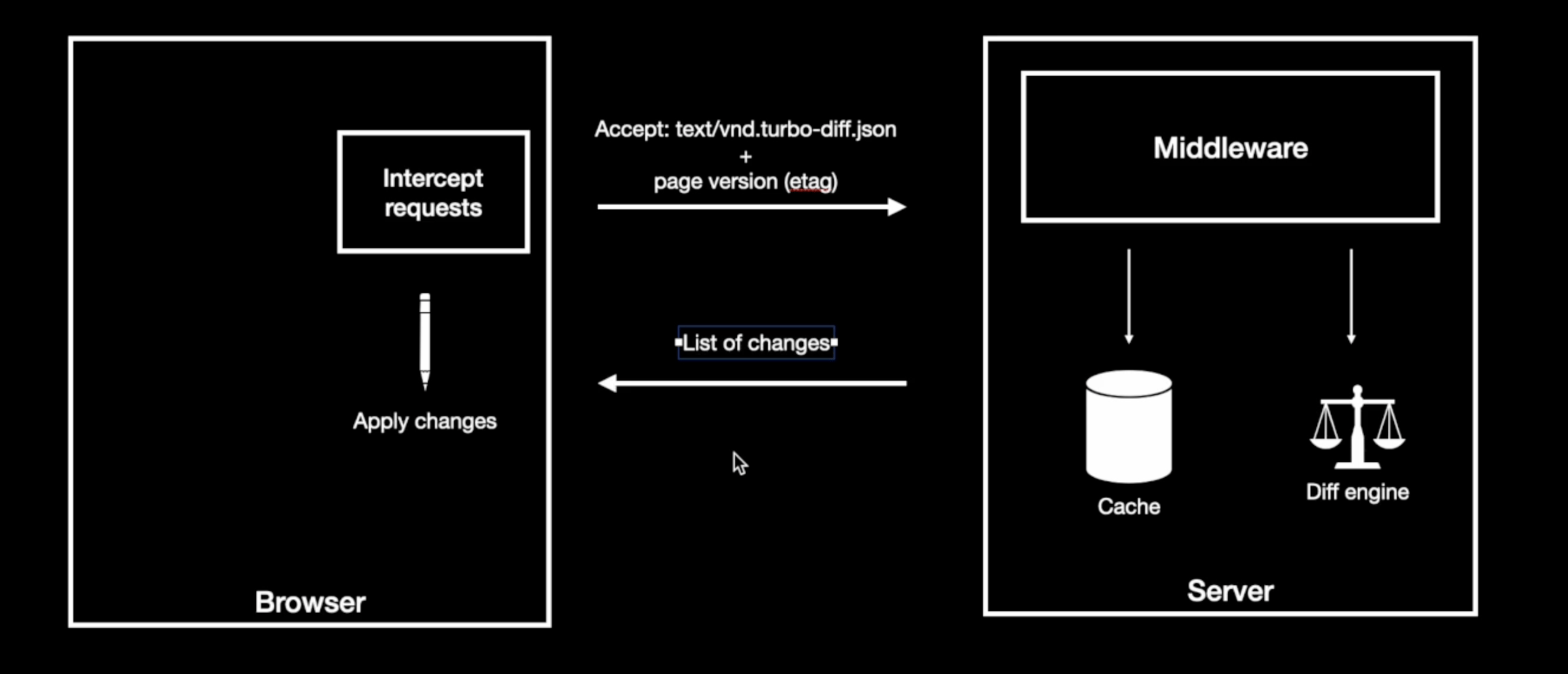
The prototype design
The diagram shows two boxes:
- On the left, the browser. It is prepared to apply the diff changes it receives from the server.
- On the right, the server. It contains a middleware that communicates with the cache and the diff engine.
The client makes requests supporting a new mime type text/vnd.turbo-diff.json. The server responds with
the list of changes.
The diff payloads are a JSON structure that identified nodes by the list of positions from the root. For example, if you had this tree:
<root>
<child-a></child-a>
<child-1 id="1"></child-1>
<child-2 id="2"></child-2>
<child-3 id="3"></child-3>
</root>
And you wanted to transform it into:
<root>
<child-b></child-b>
<child-3 id="3"></child-3>
<child-4 id="4"></child-4>
<child-5 id="5"></child-5>
</root>
The diff would be:
[
{ "type": "delete", "selector": "0/1" },
{ "type": "delete", "selector": "0/2" },
{ "type": "replace", "selector": "0/0", "html": "<child-b></child-b>" },
{ "type": "insert", "selector": "0/2", "html": "<child-4 id=\"4\"></child-4>" },
{ "type": "insert", "selector": "0/3", "html": "<child-5 id=\"5\"></child-5>" }
]
You can see the video I prepared to discuss internally the idea. It has some edited parts, and it’s shortened, but it shows an example using the prototype in HEY.
And here you can check the source code of the prototype. If you are interested, the meat of it happens in the middleware, the diff engine and the client system to apply changes. The diffing algorithm is way more relaxed than morphdom’s and can reconcile nodes when ids were missing, similar to idiomorph’s. As a curiosity, I tried nokolexbor, and it worked surprisingly well as a much faster Nokogiri replacement.
Our verdict
We discussed many things around the prototype, and we decided to go with client-side morphing. When profiling the solution, there were some marginal gains due to the smaller payload, but they weren’t noticeable in the scenarios we tested. Our approach was way more rudimentary than Phoenix Live View’s — which does deliver amazing responsiveness — but, as mentioned, we were not interested in the stateful Web Socket connection backbone. On top of that, we had some significant concerns. Jeffrey Hardy wrote a wonderful summary of those in Basecamp:
- Tracking the last-rendered page on the server is expensive, but it’s also more complicated than it appears. The client, however, already has a copy of the current page, on screen and in memory. It’s in a perfect position to reconcile differences between its current state and the incoming state from the server. The screen receiving the HTTP response is necessarily the source of truth about the current state.
- Tracking the per-client state on the server is pushing against the grain of HTTP, where statelessness is a core feature. Clients are already great at working with HTTP and its core semantics, especially browsers, and we benefit from all things they can do natively and transparently, not least of which is HTTP caching. We don’t want to reimplement a version of what the protocol does best.
- Performing DOM reconciliation on the server means we’ll end up with a decent implementation of HTML diffing in Ruby, for Rack-based servers. That’s totally fine for us, but limiting for Turbo in general, which isn’t otherwise tied to any server implementation. That backend agnosticism is one of the great things about Turbo’s design. It’s progressive enhancement: drop it into your app, and it just works (or degrades gracefully). The server needn’t be any the wiser: it just serves HTTP documents as it always has. Requiring backend cooperation and a distributed document store to enable higher-fidelity page updates is a big ask.
- While we can surely create an excellent DOM diffing library for the server that eventually covers all the edge cases we come across, do we want to?
- HTML is a document format, and while it might make sense to send fragments as an optimization, we don’t want to stray too far from the source. By speaking in HTML documents we provide a path for graceful degradation: clients know how to render HTML, no batteries required, no matter the platform. When the server doesn’t need to tailor its response for specific clients, everything is easier. The client then takes responsibility for enhancing the experience according to its capabilities, which is exactly how Turbo Drive works for navigation. There’s no reason why it can’t enhance that experience further, by intelligently reconciling incoming DOM with its current state.
Conclusion
When I described the new stuff coming in Turbo 8, I said that morphing was an implementation detail. Here, we explored an alternative to fulfill the same vision: smoother updates using regular Rails full-page rendering. I understand how “Morphing in Turbo 8” became a headline, but this is the one I prefer: “the redirect_to you love now feels smoother”.
Despite not panning out, exploring server-side diffing was a lot of fun and helped us to set a destination. This was indeed the project that inspired some thoughts about how writing code just to drop it away can be very valuable.
I started last week by deleting thousands of lines for a prototype I had built for an exciting idea we’re exploring, and I didn’t feel any remorse — quite the opposite. The prototype allowed us to test the idea in different scenarios, discuss its flaws, get key feedback, and clarify what we wanted. What I built didn’t pan out, but it was very valuable to me. After it, I felt we finally knew what we wanted to build. It brought clarity.
I appreciate working in a place that creates the space for such explorations. I did this while working on a product. Nobody asked me to do it, nobody told me not to, and I got tons of constructive insight when I reached out to folks for opinions. Favoring such investigations can be as simple as not discouraging them, even when they don’t end up with a deliverable. And the benefit of letting the people doing the job run them is that tying solutions to actual needs happens naturally.
You can learn more about the place where we landed at here.
Sign up to get posts via email,
or grab the RSS feed.