
Background
HEY currently runs on Amazon Aurora with MySQL 5.7 compatibility. It uses the InnoDB storage engine.
In InnoDB, table and indexes are stored in a variation of a B+ tree data structure. The tree is split into 16KB pages with the records stored in the leaf nodes.
The table rows are sorted by the primary key and the index records by the values of the indexed columns.
When the InnoDB pages are accessed they are loaded into memory and cached there in the buffer pool.
Query optimisation
One of the main bottlenecks for queries is loading pages from disk into memory. It follows that reducing the number of pages accessed should improve performance.
We can do this by accessing less data, or by ensuring that the data we access is stored contiguously in the same pages.
Problem
In HEY we saw that slowest queries were for pagination queries. They involved joins and filtering across multiple tables. The explain plan generally has a pattern that ends with a primary key lookup on the table we are paging from.
When paginating, unless you can read directly from an index in the required sort order, you will need to do what MySQL calls a filesort. All data that matches the query will be loaded, sorted and then the records for your page can be selected.
This is an example from the Spam page:
mysql> EXPLAIN
SELECT `topics`.*
FROM `topics`
INNER JOIN `accesses` ON `accesses`.`topic_id` = `topics`.`id`
WHERE `accesses`.`contact_id` IN (
SELECT `contacts`.`id`
FROM `contacts`
INNER JOIN `users` ON `contacts`.`contactable_id` = `users`.`id`
WHERE `users`.`identity_id` = 280304
AND `contacts`.`contactable_type` = 'User'
)
AND `topics`.`status` = 5
ORDER BY `topics`.`active_at` DESC, `topics`.`id` DESC
LIMIT 15;
+----+-------------+----------+------------+--------+-----------------------------------------------------------------------------------------------------------------+-------------------------------------------------------+---------+---------------------------------------+------+----------+----------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+--------+-----------------------------------------------------------------------------------------------------------------+-------------------------------------------------------+---------+---------------------------------------+------+----------+----------------------------------------------+
| 1 | SIMPLE | users | NULL | ref | PRIMARY,index_users_on_identity_id | index_users_on_identity_id | 8 | const | 1 | 100.00 | Using index; Using temporary; Using filesort |
| 1 | SIMPLE | contacts | NULL | ref | PRIMARY,index_contacts_on_contactable_type_and_contactable_id,index_contacts_on_contactable_type_and_account_id | index_contacts_on_contactable_type_and_contactable_id | 1030 | const,haystack_production.users.id | 1 | 100.00 | Using index |
| 1 | SIMPLE | accesses | NULL | ref | index_accesses_on_topic_id_and_contact_id,index_accesses_on_contact_id | index_accesses_on_contact_id | 8 | haystack_production.contacts.id | 493 | 100.00 | NULL |
| 1 | SIMPLE | topics | NULL | eq_ref | PRIMARY | PRIMARY | 8 | haystack_production.accesses.topic_id | 1 | 10.00 | Using where |
+----+-------------+----------+------------+--------+-----------------------------------------------------------------------------------------------------------------+-------------------------------------------------------+---------+---------------------------------------+------+----------+----------------------------------------------+
4 rows in set, 1 warning (0.00 sec)Because we are filtering on values from multiple tables, it is not possible to construct an index that will return the topics in the active_at, id sort order, hence the need for the filesort.
The performance killer is the primary key lookup on topics. Rows are ordered by primary key so the records for a single account will be spread through many InnoDB pages across disk. We need to load all the matching pages, sort them and then return the first 15.
Composite primary keys
This article from Shopify explains how they introduced “composite” primary keys in order to mitigate this type of issue. Because the rows are sorted by primary key, prefixing it with a tenant ID (in their case shop_id, in ours account_id) co-locates the tenant’s rows and reduces the number of page loads.
That article highlights again this important rule about query optimisation — you need to minimise the number of pages accessed by a query. Disk accesses are a performance killer.
Composite keys have drawbacks though — they need to be kept in sync and Shopify found that inserts were about 10x slower. However, we can use the same technique but avoid these drawbacks by using tenant ID prefixed indexes instead.
Tenant ID prefixed indexes
We’ll start by changing our query to use an index instead of a PRIMARY key lookup on the topics table.
For our query as it is written now we need an index on the topics table on id, status and active_at.
This helps a little (queries were about 2x faster) but is not enough — our index is prefixed by the primary key, so the entries we look at are spread out through the index structure, which still means lots of page loads.
What we need is an index where the entries we examine are located together. To do this we can borrow Shopify’s composite primary key approach by prefixing our index with the account_id — so an index on account_id, id, status and active_at.
Now the index entries are together in the same pages, so we need fewer disk lookups.
Using the index
This isn’t the end of the story. Building an efficient structure is one step. Convincing MySQL to use it is the next one.
Include account_id in the where clause
Firstly we need to include account_id in the query so that MySQL can use the index. We do this by adding accesses.account_id = topics.account_id.
mysql> EXPLAIN
-> SELECT `topics`.*
-> FROM `topics`
-> INNER JOIN `accesses` ON `accesses`.`topic_id` = `topics`.`id`
-> WHERE `accesses`.`contact_id` IN (
-> SELECT `contacts`.`id`
-> FROM `contacts`
-> INNER JOIN `users` ON `contacts`.`contactable_id` = `users`.`id`
-> WHERE `users`.`identity_id` = 280304
-> AND `contacts`.`contactable_type` = 'User'
-> )
-> AND `topics`.`status` = 5
-> AND `accesses`.`account_id` = `topics`.`account_id`
-> ORDER BY `topics`.`active_at` DESC, `topics`.`id` DESC
-> LIMIT 15;
+----+-------------+----------+------------+--------+-----------------------------------------------------------------------------------------------------------------+----------------------------------------------------------+---------+---------------------------------------+------+----------+----------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+--------+-----------------------------------------------------------------------------------------------------------------+----------------------------------------------------------+---------+---------------------------------------+------+----------+----------------------------------------------+
| 1 | SIMPLE | users | NULL | ref | PRIMARY,index_users_on_identity_id | index_users_on_identity_id | 8 | const | 1 | 100.00 | Using index; Using temporary; Using filesort |
| 1 | SIMPLE | contacts | NULL | ref | PRIMARY,index_contacts_on_contactable_type_and_contactable_id,index_contacts_on_contactable_type_and_account_id | index_contacts_on_contactable_type_and_contactable_id | 1030 | const,haystack_production.users.id | 1 | 100.00 | Using index |
| 1 | SIMPLE | accesses | NULL | ref | index_accesses_on_topic_id_and_contact_id,index_accesses_on_contact_id_and_account_id_and_topic_id | index_accesses_on_contact_id_and_account_id_and_topic_id | 8 | haystack_production.contacts.id | 433 | 100.00 | Using index |
| 1 | SIMPLE | topics | NULL | eq_ref | PRIMARY,index_topics_on_account_id_and_id_and_status_and_dates | PRIMARY | 8 | haystack_production.accesses.topic_id | 1 | 5.00 | Using where |
+----+-------------+----------+------------+--------+-----------------------------------------------------------------------------------------------------------------+----------------------------------------------------------+---------+---------------------------------------+------+----------+----------------------------------------------+
4 rows in set, 1 warning (0.00 sec)Note: in this query plan there’s also a new covering index to avoid looking up the accesses table: index_accesses_on_contact_id_and_account_id_and_topic_id
Force the index
MySQL is still doing a primary key lookup on the topics table, so we are still slow — but we can force the index:
mysql> EXPLAIN
-> SELECT `topics`.*
-> FROM `topics` FORCE INDEX(index_topics_on_account_id_and_id_and_status_and_dates)
-> INNER JOIN `accesses` ON `accesses`.`topic_id` = `topics`.`id`
-> WHERE `accesses`.`contact_id` IN (
-> SELECT `contacts`.`id`
-> FROM `contacts`
-> INNER JOIN `users` ON `contacts`.`contactable_id` = `users`.`id`
-> WHERE `users`.`identity_id` = 280304
-> AND `contacts`.`contactable_type` = 'User'
-> )
-> AND `topics`.`status` = 5
-> AND `accesses`.`account_id` = `topics`.`account_id`
-> ORDER BY `topics`.`active_at` DESC, `topics`.`id` DESC
-> LIMIT 15;
+----+-------------+----------+------------+------+-----------------------------------------------------------------------------------------------------------------+----------------------------------------------------------+---------+-------------------------------------------------------------------------------------+------+----------+----------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+-----------------------------------------------------------------------------------------------------------------+----------------------------------------------------------+---------+-------------------------------------------------------------------------------------+------+----------+----------------------------------------------+
| 1 | SIMPLE | users | NULL | ref | PRIMARY,index_users_on_identity_id | index_users_on_identity_id | 8 | const | 1 | 100.00 | Using index; Using temporary; Using filesort |
| 1 | SIMPLE | contacts | NULL | ref | PRIMARY,index_contacts_on_contactable_type_and_contactable_id,index_contacts_on_contactable_type_and_account_id | index_contacts_on_contactable_type_and_contactable_id | 1030 | const,haystack_production.users.id | 1 | 100.00 | Using index |
| 1 | SIMPLE | accesses | NULL | ref | index_accesses_on_topic_id_and_contact_id,index_accesses_on_contact_id_and_account_id_and_topic_id | index_accesses_on_contact_id_and_account_id_and_topic_id | 8 | haystack_production.contacts.id | 433 | 100.00 | Using index |
| 1 | SIMPLE | topics | NULL | ref | index_topics_on_account_id_and_id_and_status_and_dates | index_topics_on_account_id_and_id_and_status_and_dates | 20 | haystack_production.accesses.account_id,haystack_production.accesses.topic_id,const | 1 | 100.00 | NULL |
+----+-------------+----------+------------+------+-----------------------------------------------------------------------------------------------------------------+----------------------------------------------------------+---------+-------------------------------------------------------------------------------------+------+----------+----------------------------------------------+This looks much better — but it was still slow! It’s not clear from the explain plan, but MySQL still loaded all the topic records and then sorted them even though the sort columns were stored in the index. This is a similar problem to the one the fast page gem is designed to fix.
Restrict the selected columns
This was the final piece of the puzzle — if we restrict the query to only select columns in our index, then MySQL gives in and stops accessing the topics table:
mysql> EXPLAIN
-> SELECT `topics`.`id`, `topics`.`active_at`
-> FROM `topics` FORCE INDEX(index_topics_on_account_id_and_id_and_status_and_dates)
-> INNER JOIN `accesses` ON `accesses`.`topic_id` = `topics`.`id`
-> WHERE `accesses`.`contact_id` IN (
-> SELECT `contacts`.`id`
-> FROM `contacts`
-> INNER JOIN `users` ON `contacts`.`contactable_id` = `users`.`id`
-> WHERE `users`.`identity_id` = 280304
-> AND `contacts`.`contactable_type` = 'User'
-> )
-> AND `topics`.`status` = 5
-> AND `accesses`.`account_id` = `topics`.`account_id`
-> ORDER BY `topics`.`active_at` DESC, `topics`.`id` DESC
-> LIMIT 15;
+----+-------------+----------+------------+------+-----------------------------------------------------------------------------------------------------------------+----------------------------------------------------------+---------+-------------------------------------------------------------------------------------+------+----------+----------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+-----------------------------------------------------------------------------------------------------------------+----------------------------------------------------------+---------+-------------------------------------------------------------------------------------+------+----------+----------------------------------------------+
| 1 | SIMPLE | users | NULL | ref | PRIMARY,index_users_on_identity_id | index_users_on_identity_id | 8 | const | 1 | 100.00 | Using index; Using temporary; Using filesort |
| 1 | SIMPLE | contacts | NULL | ref | PRIMARY,index_contacts_on_contactable_type_and_contactable_id,index_contacts_on_contactable_type_and_account_id | index_contacts_on_contactable_type_and_contactable_id | 1030 | const,haystack_production.users.id | 1 | 100.00 | Using index |
| 1 | SIMPLE | accesses | NULL | ref | index_accesses_on_topic_id_and_contact_id,index_accesses_on_contact_id_and_account_id_and_topic_id | index_accesses_on_contact_id_and_account_id_and_topic_id | 8 | haystack_production.contacts.id | 433 | 100.00 | Using index |
| 1 | SIMPLE | topics | NULL | ref | index_topics_on_account_id_and_id_and_status_and_dates | index_topics_on_account_id_and_id_and_status_and_dates | 20 | haystack_production.accesses.account_id,haystack_production.accesses.topic_id,const | 1 | 100.00 | Using index |
+----+-------------+----------+------------+------+-----------------------------------------------------------------------------------------------------------------+----------------------------------------------------------+---------+-------------------------------------------------------------------------------------+------+----------+----------------------------------------------+Victory at last! Instead of lots of random accesses in the topics table we are looking up records in the index_topics_on_account_id_and_id_and_status_and_dates index.
Loading the full records
One final issue — we are not loading the full topic records anymore. So we’ll need to a second query to load the records by the returned IDs. Though using a primary key lookup, this query only has to access the 15 matching records so it very fast.
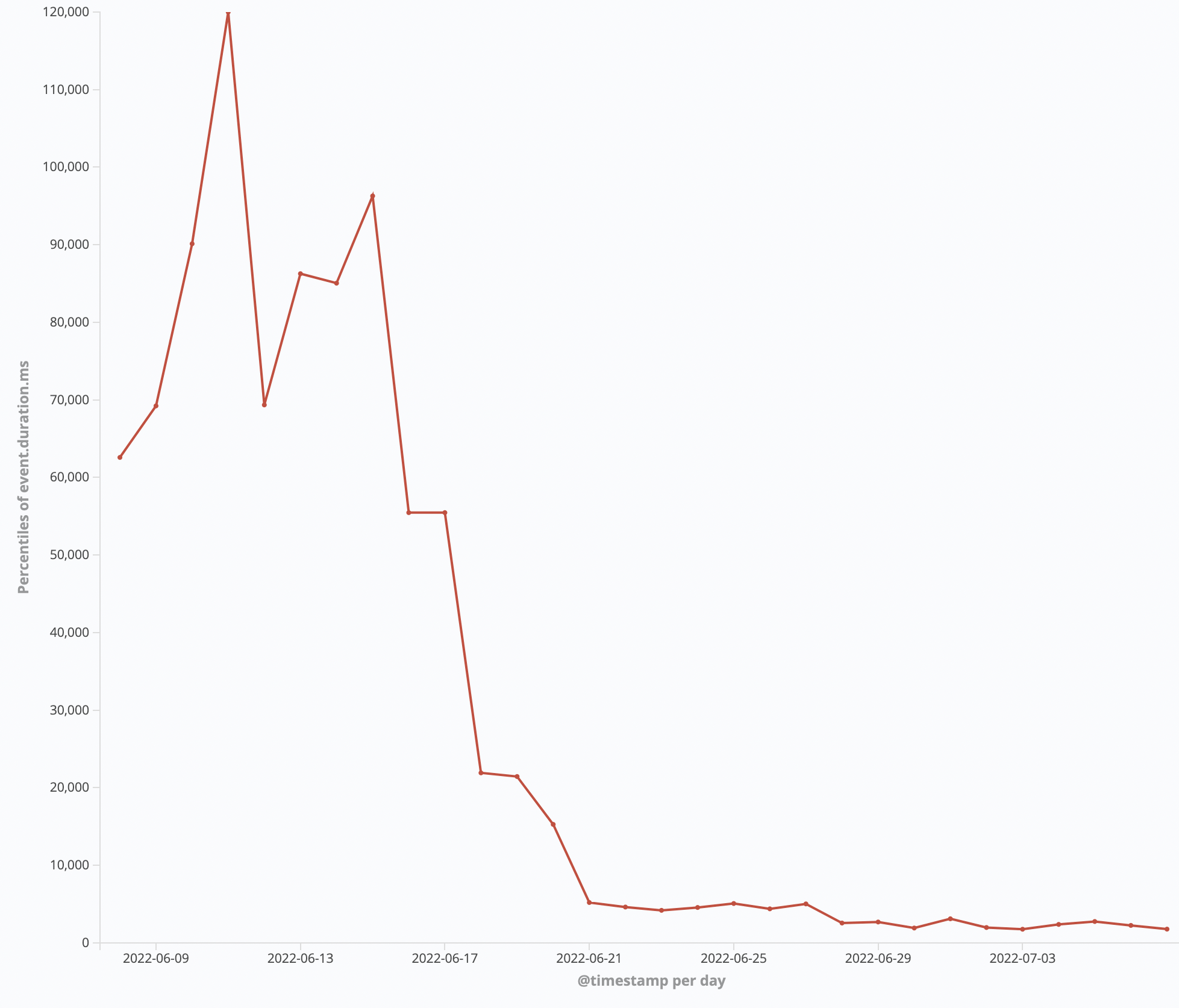
Results
We can see the massive fall in the time of the 99.99 percentile for Spam requests:
Re-cap
The steps to speed up the query were:
- Create a covering index on the topics table prefixed by
account_id - Modify the query to include a join by
account_id, and to only select columns in our index - Force MySQL to use the index
- Add a second query to load the full row
Conclusion
Indexes are a useful tool for query optimisation but they are not magic. If we step down a level we find that they are made up of pages. Fewer page accesses mean faster queries.
Sign up to get posts via email,
or grab the RSS feed.